Khả năng tiên tiến của ChatGPT, chẳng hạn như sửa lỗi mã code, viết một bài luận hoặc nói đùa, đã đưa nó trở thành một xu hướng phổ biến. Mặc dù có khả năng đáng kinh ngạc, sự hỗ trợ của nó đã giới hạn chỉ trong văn bản -- nhưng điều đó sẽ sớm thay đổi.
Vào thứ ba, OpenAI đã ra mắt GPT-4, một mô hình đa phương thức lớn có thể nhận cả đầu vào văn bản và hình ảnh và đưa ra đầu ra là văn bản.
Ngoài ra: Cách làm cho ChatGPT cung cấp nguồn và trích dẫn
Sự khác biệt giữa GPT-3.5 và GPT-4 sẽ là "tinh tế" trong cuộc trò chuyện thông thường. Tuy nhiên, mô hình mới sẽ có khả năng đáng tin cậy, sáng tạo và thậm chí thông minh hơn rất nhiều.
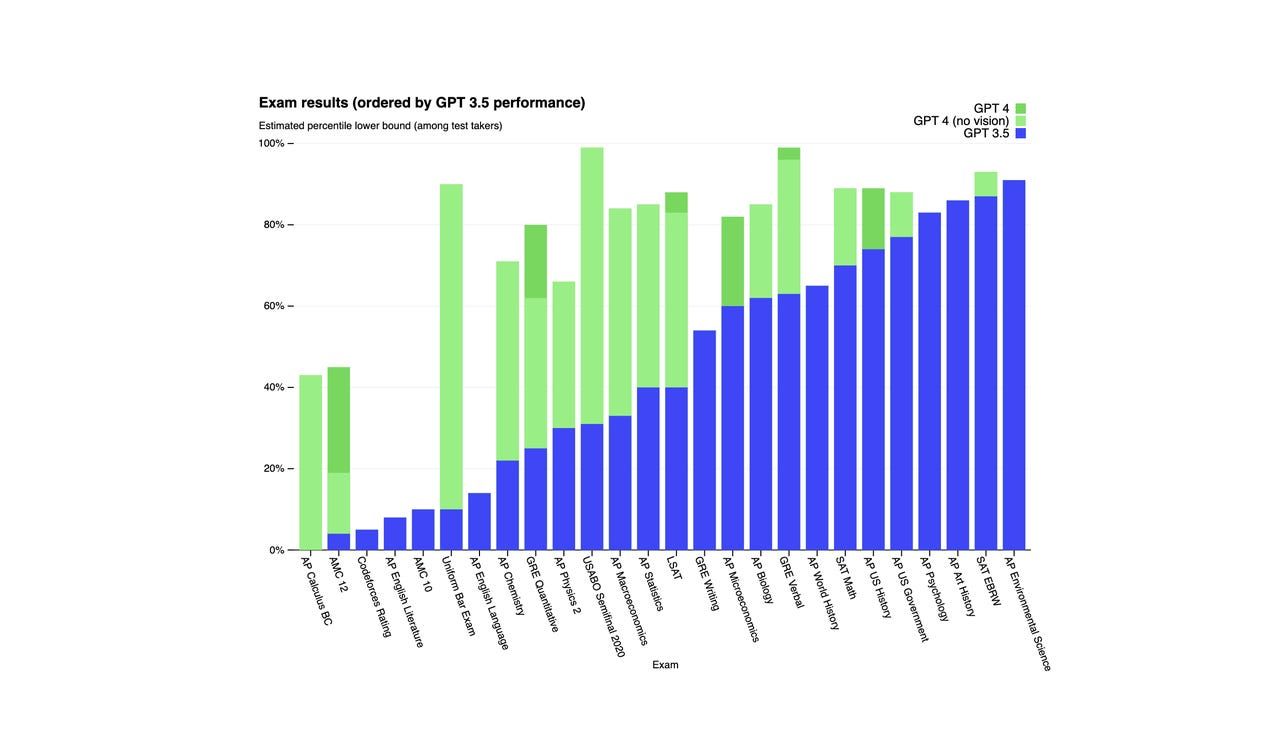
Theo OpenAI, GPT-4 đạt điểm trong 10% hàng đầu của bài kiểm tra mô phỏng trên quy mô quốc gia, trong khi GPT-3.5 đạt điểm ở khoảng 10% cuối. GPT-4 cũng vượt trội hơn GPT-3.5 trong một loạt các bài kiểm tra mức độ thực nghiệm, như được thấy trong biểu đồ dưới đây.

Để hiểu rõ hơn, ChatGPT hoạt động dựa trên một mô hình ngôn ngữ được điều chỉnh lại từ một mô hình trong loạt 3.5, giới hạn chatbot chỉ có thể đưa ra đầu ra là văn bản.
Thông báo về GPT-4 của OpenAI được đưa ra sau một bài phát biểu từ Andreas Braun, Giám đốc Công nghệ của Microsoft Đức, tuần trước. Trong bài phát biểu đó, ông cho biết GPT-4 sẽ sớm được ra mắt và cho phép việc tạo ra video từ văn bản.
Cũng: Làm thế nào để ChatGPT hoạt động?
"Chúng tôi sẽ giới thiệu GPT-4 vào tuần sau; ở đó chúng tôi sẽ có các mô hình đa phương thức mà sẽ mang đến những khả năng hoàn toàn khác biệt -- ví dụ như video," Braun nói theo Heise, một trang tin tức Đức tại sự kiện.
Mặc dù GPT-4 là đa phương thức, nhưng công việc tạo ra video từ văn bản của nó có phần không chính xác. Mô hình chưa thể tạo ra video hoàn chỉnh, nhưng nó có thể nhận đầu vào hình ảnh, điều này là một thay đổi lớn so với mô hình trước đó.
Một trong những ví dụ mà OpenAI cung cấp để trình diễn tính năng này cho thấy ChatGPT quét một hình ảnh để tìm hiểu điều gì về bức ảnh làm cho nó trở nên hài hước, dựa trên đầu vào từ người dùng.
Các ví dụ khác bao gồm việc tải lên một hình ảnh của một biểu đồ và yêu cầu GPT-4 thực hiện tính toán từ đó hoặc tải lên một bảng công và yêu cầu nó giải các câu hỏi.
Cũng: 5 cách ChatGPT có thể giúp bạn viết một bài luận
OpenAI cho biết họ sẽ phát hành khả năng nhập liệu văn bản của GPT-4 thông qua ChatGPT và API thông qua danh sách chờ. Bạn sẽ phải chờ lâu hơn một chút cho tính năng nhập liệu hình ảnh vì OpenAI đang hợp tác với một đối tác duy nhất để bắt đầu việc đó.
Nếu bạn thất vọng vì không có bộ tạo video từ văn bản, đừng lo, điều đó không phải là một khái niệm hoàn toàn mới. Các công ty công nghệ lớn như Meta và Google đã có mô hình đang trong quá trình phát triển. Meta có Make-A-Video và Google có Imagen Video, cả hai đều sử dụng trí tuệ nhân tạo để tạo ra video từ đầu vào của người dùng.